대규모 언어 모델(LLM) 훈련은 상당한 양의 메모리와 컴퓨팅 파워를 요구합니다. 예를 들어, LLaMA 7B 모델을 처음부터 사전 훈련하려면 단일 배치 크기에 최소 58GB의 메모리가 필요합니다. 이러한 메모리 문제를 완화하기 위해 등장한 한 방법은 Low-rank Adaptation (LoRA)입니다. 이 접근 방식은 각 계층에 훈련된 Low-rank 행렬을 추가함으로써 파라미터의 수를 줄입니다. 그러나, 이 방법은 Low-rank subspace 내에서 파라미터 검색을 제한하고, 학습을 다이나믹하게 변경하며, full-rank 의 웜 스타트를 필요로 할 수 있어, full-rank 가중치로 훈련했을 때보다 열등한 성능을 초래할 수 있습니다.
GaLore: Gradient Low-Rank Projection
Gradient Low-Rank Projection (GaLore) 은 LoRA와 같은 전통적인 low-rank 방법보다 더 큰 메모리 효율성을 가진 전체 파라미터 학습을 가능하게 하는 훈련 전략을 제시합니다. GaLore는 최적화 상태 내 메모리 사용량을 최대 65.5%까지 줄이며, LLaMA 1B 및 7B 아키텍처에서의 사전 훈련과 RoBERTa에서의 GLUE 작업 세밀 조정을 통해 효율성과 성능을 유지합니다. 특히, 8비트 GaLore는 BF16 표준에 비해 최적화 메모리를 최대 82.5%까지, 전체 훈련 메모리를 63.3%까지 감소시켜, NVIDIA RTX 4090과 같은 소비자 등급 GPU에서 모델 병렬 체크포인트 또는 오프로딩 전략 없이 7B 모델의 사전 훈련을 가능하게 합니다.

GaLore는 LoRA에 의해 보여진 한계를 극복하고 전통적인 저차원 적응 방법보다 훨씬 더 메모리 효율적인 전체 파라미터 학습을 허용합니다. 주요 아이디어는 저차원으로 가중치 행렬 자체를 저차원으로 근사하려는 시도 대신, 가중치 행렬 W의 그라데이션 G의 천천히 변화하는 저차원 구조를 활용하는 것입니다.
가중치 업데이트 공식: 주어진 훈련 단계 t에서의 가중치 W_t는 공식에 따라 업데이트됩니다.

서브스페이스 스위칭:
모델은 훈련 중에 동적으로 저차원 서브스페이스를 전환합니다. 서브스페이스의 선택은
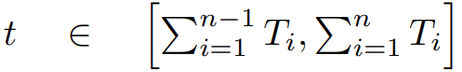
에 의해 결정된 일정에 기반하여 이루어지며, 여기서 T_i는 i번째 서브스페이스 내에서의 업데이트 횟수를 나타냅니다.
이 기술은 대규모 신경망의 훈련을 최적화하는 복잡한 접근 방법입니다. 다양한 부공간을 신중하게 탐색함으로써, 모델은 가중치 공간을 더 효율적으로 탐색할 수 있으며, 이는 더 나은 일반화 및 성능으로 이어질 수 있습니다. 이 방법은 LLM의 가중치 공간의 복잡성을 인식하고 SVD와 같은 수학적 도구를 활용하여 훈련을 더 효과적이고 효율적으로 만듭니다.

논문에서는 여러 도구들을 사용하여 실험을 하였고 GaLore가 얼마나 메모리 효율성을 보여주는지 결과를 이 표에서 보여주고 있습니다.실험 설정은 다음과 같습니다.
- GaLore의 경우, 서브스페이스 빈도 T는 200으로 고정되며, 모든 모델 크기에 걸쳐 스케일 인자 α는 0.25로 적용됩니다.
- 각 모델 크기에 대해 모든 저차원 방법에 대해 일관된 순위 r이 선택되며, 이 방법들은 모델 내의 모든 멀티-헤드 어텐션 및 피드-포워드 레이어에 적용됩니다.
- Adam 최적화 기능을 사용하여, 기본 하이퍼파라미터를 따라 훈련이 수행됩니다.
- 메모리 사용량은 BF16 포맷을 기반으로 추정되며, 가중치 매개변수와 최적화 상태에 필요한 메모리를 고려합니다.
표에 나오는 데이터를 비교해 보면 GaLore가 다른 방법들을 능가하며, full-Rank 훈련에 가까운 성능을 보여주는 것을 알 수 있습니다. 특히, 1B 모델 크기의 경우, GaLore는 ‘r = 512’ 대신 ‘r = 1024’를 사용할 때 full-rank 기준 성능을 초과합니다. 또한, LoRA 및 ReLoRA와 비교할 때, GaLore는 모델 매개변수와 최적화 상태를 저장하기 위해 더 적은 메모리를 요구합니다.
결론
GaLore는 대규모 언어 모델(LLMs)의 사전 훈련 및 미세 조정 동안 메모리 사용량을 크게 줄이면서도 성능을 유지합니다. 이는 대형 컴퓨팅 시스템에 대한 의존도가 감소하고 상당한 비용 절감 가능성을 시사합니다. 그러나, 논문에서는 GaLore가 여전히 해결되지 않은 문제들을 직면하고 있음을 인정합니다: 비전 트랜스포머 및 확산 모델과 같은 다양한 유형의 훈련에 적용, 양자화 및 특수 파라미터화를 통한 메모리 효율성의 추가 개선, 그리고 소비자 등급 하드웨어에서 탄력적 데이터 분산 훈련의 잠재력 탐색 등이 그것입니다.
이러한 해결되지 않은 문제에도 불구하고, GaLore는 소비자 등급 하드웨어를 사용하여 LLM의 훈련을 용이하게 하여 보다 넓은 참여를 가능하게 합니다. 이러한 접근성 향상은 LLM 연구의 발전을 가속화할 수 있으며, 더 많은 커뮤니티의 참여를 통해 GaLore가 현재의 도전을 극복하고 LLM 커뮤니티에 가치 있는 도구로 발전하기를 기대합니다.
Reference:
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection (arxiv.org)
'IT' 카테고리의 다른 글
| 최신 AI 언어 모델 ChatGPT 4-o의 혁신적인 기능 소개 (0) | 2024.06.07 |
|---|---|
| OpenAI 신규 업데이트 발표!! 영화 HER 현실이 되나 (0) | 2024.05.14 |
| Git 브랜치 전략 (2) | 2024.03.07 |
| AI 채팅을 내 컴퓨터에서 실행하기: LLAMA2 with Text generation web UI (0) | 2024.03.07 |
| 아마존의 AI 코드 자동 생성기 Amazon CodeWhisperer 설치 및 사용 (1) | 2023.04.25 |



